
I know (?) that this sounds like another one of my dumb questions.
But since academics and other professionals are in the knowledge business, it’s worth our considering the question, which we will discuss in this installment of the Stone Soup mini-course.
We all know that 2+2=4, Google is a search engine, and murder is illegal.
But lots of things are dicier. Does God exist? Is the Mona Lisa a beautiful painting? Is capitalism the best system of political economy? Did the Supreme Court correctly apply the law in Bush v. Gore? Etc.
There are many types of knowledge, including theological, aesthetic, political philosophy, and legal doctrine, among many others. In this mini-course, I will focus only on social scientific knowledge.
Science involves systematic empirical observation to produce the best possible description of the real world and how it works. Common methods of social science research include experiments, surveys, interviews, focus groups, observations, and analysis of “artifacts” like documents, among others.
How Do You Know What (You Think) You Know?
Of course, you can be confident of knowing what you see, right? Wrong.
You may be familiar with the popular law school demonstration in which a professor arranges for someone to barge into class, do something outrageous, and quickly leave. The professor asks students to write what they saw, presumably as evidence for the police. As you probably know (or guessed), many of the the students’ accounts are inaccurate despite the fact that they had witnessed the events just moments earlier. Behavioral economists, like Daniel Kahneman, have documented numerous cognitive errors that people regularly make. So when Groucho Marx asks, “Who you gonna believe? Me or your own eyes?,” sometimes you should believe Groucho.
If you can’t believe your own eyes, certainly you can believe videotape, right? Wrong.
Think about all the news stories with videos of police shootings, where people see the same videos and have dramatically different accounts of the events. Or consider false videotaped confessions by criminal defendants and hostages. To really know what happened, you would have to have a comprehensive set of videos, starting well before the videos were produced and from many angles.
Eye witness accounts and videotapes are just individual pieces of evidence, but after court trials with lots of evidence, certainly the truth will be determined correctly, right? Wrong.
With some regularity, there are hung juries and decisions that are reversed based on erroneous factual determinations, such as wrongful convictions.
Although sometimes we appropriately feel we know the facts about specific incidents, sometimes what we “know” is wrong, and there are many things we don’t know – or are uncertain about.
But We Can Be Confident About Quantitative Data, Right?
I suspect that a lot of people don’t think carefully about this and assume that quantitative social science data reveals some general truth. But they are wrong.
Of course, quantitative data can provide reasonable inferences about the world, but it is embedded with many implicit assumptions that should cause people to be cautious. Researchers use procedures to reduce errors and their reports recognize potential “threats to validity.” They tend to be more cautious about making inferences from quantitative data than laypeople.
The frequency of a phenomenon in a population is a simple descriptive statistic that can be estimated with quantitative surveys. To generate the statistic, you select a sample and calculate statistics from the sample data on the assumption that the sample is generalizable to the population.
It can be tricky to select samples because there can be “selection bias” if the sample systematically differs from the population. An extreme example is when political news networks take polls of viewers. A conservative news channel might find that 90% of the respondents favor a conservative proposal and a liberal channel might find that 90% oppose the same proposal. Obviously, both statistics represent the opinions of the self-selected viewers of their channels and neither statistic is a good estimate of the views of the general population.
The best way to get a representative sample of the population is to select a random sample. To do this, you should have a list of all the members of the population and then use a system to randomly select members for the sample. Often, there is no list of population members. Pollsters who conduct political surveys don’t have lists of the entire population but they use procedures that generally are considered to do a decent, though imperfect, job of selecting random samples.
The question of presidential job approval is one of the most commonly asked poll questions. Consider the following graph of poll results of President Trump’s job approval. Each dot represents the finding of one poll, and the solid lines represent the average of the poll results on a given day. Notice that there are coherent patterns, as the red and black dots generally bunch together. However, there are some “outliers,” which are far from the average. Looking at the results of a lot of polls, you can get a pretty confident understanding of presidential job approval by the general public.
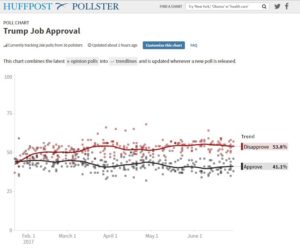
How do you know the accuracy of any single poll? Are the results near the real level of public opinion, well above it, or well below it? This is hard to tell if you don’t have any other poll results to compare it to. Using statistical theory based on the assumption of random sampling, you can calculate “confidence intervals.”
Scientists conventionally use the norm of a 95% confidence interval. For example, if a poll shows a 50% approval rating, the 95% confidence interval might be that the “true” approval in the population might be 50% ± 4%, i.e., between 46% and 54%. This means that if the poll was conducted exactly the same way 100 times, 95 times the result would vary between 46% and 54% due to random variations. Clever readers will realize that in 5 of the polls, the result would be less than 46% or greater than 54%. So you can’t know for certain that the true value in the population is 50% or even between 46% and 54%.
The size of the confidence interval is based on the sample size. The larger the sample, the smaller the confidence interval, i.e., the more confidence you should have in the results. For example, with a larger sample, the 95% confidence interval might be 50% ± 3%, or better yet, 50% ± 2%. But even under the best of circumstances, the results are approximations and there is a chance that the approximations are incorrect.
Some quantitative research is intended to determine if there is a real difference between two things. In the political context, we see this in election polling about whether one candidate is ahead of the other. For example, if a poll shows Candidate X leading Candidate Y, 50% to 46%, does that mean that Candidate X really is ahead?
To answer the question, you need to consider the confidence intervals. Assuming that the 95% confidence interval is ± 3%, that means that there is a 95% chance that Candidate X has 47% to 53% support and that Candidate Y has 43% to 49% support. Clever readers will notice that the confidence intervals overlap and that, within the 95% confidence intervals, it is possible that Candidate Y is ahead 49% to 47% in the actual population of voters despite the results from the sample showing that Candidate X is ahead.
It is not possible to use random sampling for a lot of survey research, which makes it much harder to generalize survey results to the population. In these situations, there are techniques to try to correct for sampling biases, but they are based on more tenuous assumptions than those for random sampling.
That’s Nice, But What Does It Have to Do With Dispute Resolution?
The short answer is that quantitative research about dispute resolution has many more difficulties than political polling and so we need to be especially careful in interpreting quantitative research about DR. Moreover, our quantitative research provides less confidence than laypeople may assume and isn’t necessarily better in exploring empirical reality than qualitative research.
Of course, quantitative research is very helpful in answering some questions. Well-designed research can produce good estimates about populations of interest and test hypotheses about the causal effect of particular variables on certain outcomes.
My purpose in this post is to caution laypeople about having exaggerated confidence in what they can know about dispute resolution from quantitative research.
Laboratory experiments about DR generally use random sampling, but the generalizability of these results to the real world is questionable because they eliminate many contextual variables and often use subjects (like students) who are different from people dealing with disputes in the real world.
In field studies involving actual cases, it is difficult to use random sampling and so there is a greater risk of self-selection bias. For example, if you issue a general invitation for people to complete an online survey, you risk getting a disproportionate number of respondents with strong, extreme views and relatively few respondents with mixed or weak opinions. In such situations, it is hard to know how well the results approximate the reality – and you can’t calculate confidence intervals.
The concepts and questions we use in DR research are way more complicated than in political polling. People generally know what it means to approve of the president’s job performance or to support Candidate X or Y. They may not understand our terminology – heck, we don’t even have clear, consistent understandings of our language.
Some quantitative DR studies focus on very specific variables like the duration of cases, outcomes, and elements of decisions, which are easier to understand and measure than complex processes that unfold over time.
To get valid data in response to a survey question, all the respondents should understand what the researcher intends to ask and have the same understanding of the question and response options as all the other respondents. They should be able to map their understanding of the situation closely onto the concepts in the question and find a response option that reflects their desired response. This sounds easy, but actually it is extremely difficult.
The questions in our quantitative studies often are pretty fuzzy. If we ask parties about their satisfaction with a mediation process that lasted several hours, they may have complicated reactions based on different things that happened during the mediation. Slight changes in the wording can yield substantial changes in the results. Being forced to choose from the response options they are given, respondents may have to pick one that doesn’t fit what they really think. Generally, respondents can’t ask for clarifications, which would permit more accurate responses for particular respondents but would undermine the standardization of the study.
For these and many other reasons, you may be able to generate impressive-looking numerical data from surveys that do not accurately reflect reality.
Often, we want to compare the results of two different conditions. For example, are parties who go through a mediation process more satisfied than parties who use another process? If the 95% confidence intervals of the two groups in a study don’t overlap, this generally is considered to be a statistically significant difference, supporting an inference that there was a difference in the two processes that led to differences in the satisfaction levels.
But how do we know whether this study was an outlier, like one of the dots on the presidential approval graph that was far away from the average? We don’t know how generalizable the results are if this study is the only one analyzing this issue. Unlike polls about presidential approval, there are relatively few studies about DR. If there are several studies measuring the exact same variables that reach similar results, we have more confidence that the results accurately reflect reality. They are considered “robust” and are not just a statistical fluke.
A huge problem for DR research, however, is that the studies are almost always different, which makes it harder to compare “apples” with “apples” unlike polls that ask similar, simple questions.
For example, how generalizable are results from studies of family mediation to those analyzing mediation in other contexts? Is the process the “same” if lawyers participate or not? What if the process involves joint sessions or not? What if mediators use different interventions, e.g., those considered as “facilitative” or “evaluative”? What if mediation is court-ordered – or conducted early in a conflict or on the eve of trial? Is mediation conducted in one location 10-20 years ago the same as mediation conducted today in another location? We can generate a long list of variables that could affect the results.
This large set of potential alternative explanations affects how much of the variance can be explained by a supposed causal factor. For a trivial illustration, if you know the number of inches of the length of an object, you can explain 100% of the variance in the length in feet. Much social scientific research explains only a small proportion of the variance. So even if a study indicates a statistically significant relationship between variables (such as DR process and level of satisfaction), it may not explain a lot of the variance considering all the other variables involved (such as the ones listed in the preceding paragraph).
Of course, quantitative research about DR can be helpful. As this discussion shows, however, laypeople should be careful in interpreting such research results.
So What Can You Know and How Can You Know It?
Without divine omniscience, it is virtually impossible to truly and fully understand the general nature of dispute resolution. Indeed, for most things, it is impossible to truly be certain of the truth. The best we can do is to increase the necessarily limited level of confidence in our beliefs.
I write all this to help people understand that quantitative research about DR usually does not produce “truth” that can be readily generalized. People should not assume that it necessarily is the best source of knowledge and that other sources are inferior.
Based on exaggerated confidence in the generalizability of quantitative research, some people believe that qualitative research is too subjective and ungeneralizable to be valid and useful. Qualitative research, they assume, merely produces anecdotes or “war stories” that can’t generate real knowledge you can rely on.
Quantitative and qualitative research are not mutually exclusive. They have complementary strengths and weaknesses as methods of producing valid knowledge. So you can really increase your understanding by using both methods in combination.
My next post will show how qualitative research can be especially useful to understand dispute resolution processes, offering improved insights and perspectives.

A comedian opined that knowledge is knowing a tomato is a fruit. Wisdom is not putting it in fruit salad.